


Editor's note: This post was updated on 15 January 2025 to include new SRE tools and update the capabilities of each tool.
Intro
Site reliability engineers (SREs) play a crucial role in maintaining the reliability, performance, and scalability of production systems. To achieve these goals, SREs rely on a variety of tools that fall into several categories, including monitoring/observability, on-call and incident management, and configuration, and automation. Here, we discuss ten essential tools that can help you make site reliability engineering easier, including both open-source options and commercial solutions.
{{cta-demo-baner}}
Monitoring and observability tools
1. Prometheus

Prometheus is an open-source systems monitoring and alerting toolkit originally built at SoundCloud. Now part of CNCF, Prometheus has grown to become an integral part of how many organizations monitor their services by making time-series data more accessible and interpretable.
Prometheus is highly flexible and integrates with many different data exporters that gather information about your entire software development pipeline, and visualizing tools that help you contextualize and present data. Prometheus’s powerful data model and query language, PromQL, helps you surface information about your system, such as its performance and reliability, while integrations like Grafana handle visualization.
2. Grafana

Grafana is an open-source, composable platform for monitoring and observability. It allows you to query, visualize, and analyze your metrics no matter where they are stored. Its powerful visualization capabilities make it an indispensable tool for SREs because of how much it can do — from gathering AI/ML insights to alert triggering and load testing.
Aside from integrating with tools like Prometheus and 300 other popular platforms, Grafana enables you to create dashboards that provide real-time insights into system health and performance.
3. Datadog

Datadog offers features such as APM (Application Performance Monitoring), log management, and security monitoring, making it a versatile tool for SREs to ensure production readiness.
Datadog is a commercial monitoring and analytics platform for cloud-scale applications. It integrates with various services and tools, providing comprehensive visibility into the performance of applications and infrastructure.
4. New Relic

New Relic is another commercial observability platform that provides real-time insights into application performance and infrastructure. It combines application, infrastructure, and real-user monitoring to offer SREs deeper insights into production readiness.
New Relic's comprehensive monitoring capabilities, intuitive interface, and automations make it a valuable tool for identifying and resolving performance issues quickly. Dashboards and orchestration capabilities make it possible to rally your team when you need to share information about how routine, unplanned, and incident changes impact your development environment.
On-call and incident management tools
5. PagerDuty

PagerDuty is a commercial incident management platform that helps SREs manage and resolve incidents faster. It provides on-call scheduling, alerting, and escalation policies, ensuring that critical issues are addressed promptly. You’ll also be able to manage any status pages you need easily, which helps speed up and improve communication with any incident stakeholders, like customers or your support team.
PagerDuty’s integration with various monitoring tools make it possible for you and your team to seamlessly detect incidents across your stack and resolve them, improving overall system reliability.
6. Incident.io
Incident.io is a commercial platform for full-stack incident management. With features like integrated on-call schedule management, unified alerting, and powerful workflow automation, Incident.io offers an improved incident response experience from end to end.

With tools that help you build a routine for incident response, reducing the anxiety and chaos of responding to alerts about a system outage or another vulnerability. This can help you focus on what needs to be done, rather than coordinating your team and developing.
Configuration and automation tools
7. Jenkins

Jenkins is an open-source automation server that supports building, deploying, and automating any project. Many continuous integration and continuous delivery (CI/CD) pipelines rely on Jenkins because it integrates with nearly every tool involved in CI/CD, making it both flexible and familiar.
For SREs, Jenkins provides the ability to automate routine tasks and ensure that code changes are consistently and reliably tested and deployed. Its distribution models can also help SREs with load balancing and higher-level systems adjustments to improve service reliability.
8. Terraform

Terraform is an open-source infrastructure as code (IaC) tool that allows you to define and provision data center infrastructure using a declarative configuration language. You can automate when and how you provision and manage infrastructure at the code level, ensuring consistency and reliability.
Terraform can manage infrastructure lifecycle, versioning, and modularity, which means saving time re-provisioning routine environments for maintenance.
Internal developer portals
9. Port
Port's internal developer portal provides a centralized hub for managing all aspects of software delivery, infrastructure, and incident management. Port’s portal helps SREs ensure production readiness by offering features such as:
- A full service catalog and their service owners
- End-to-end deployment tracking
- Automated compliance checks and scorecards, to monitor compliance with deployments
- Integrations with every service, deployment tool, and more to provide a universal view of your software development environment
- Dependency graphing for better incident mapping with blueprints
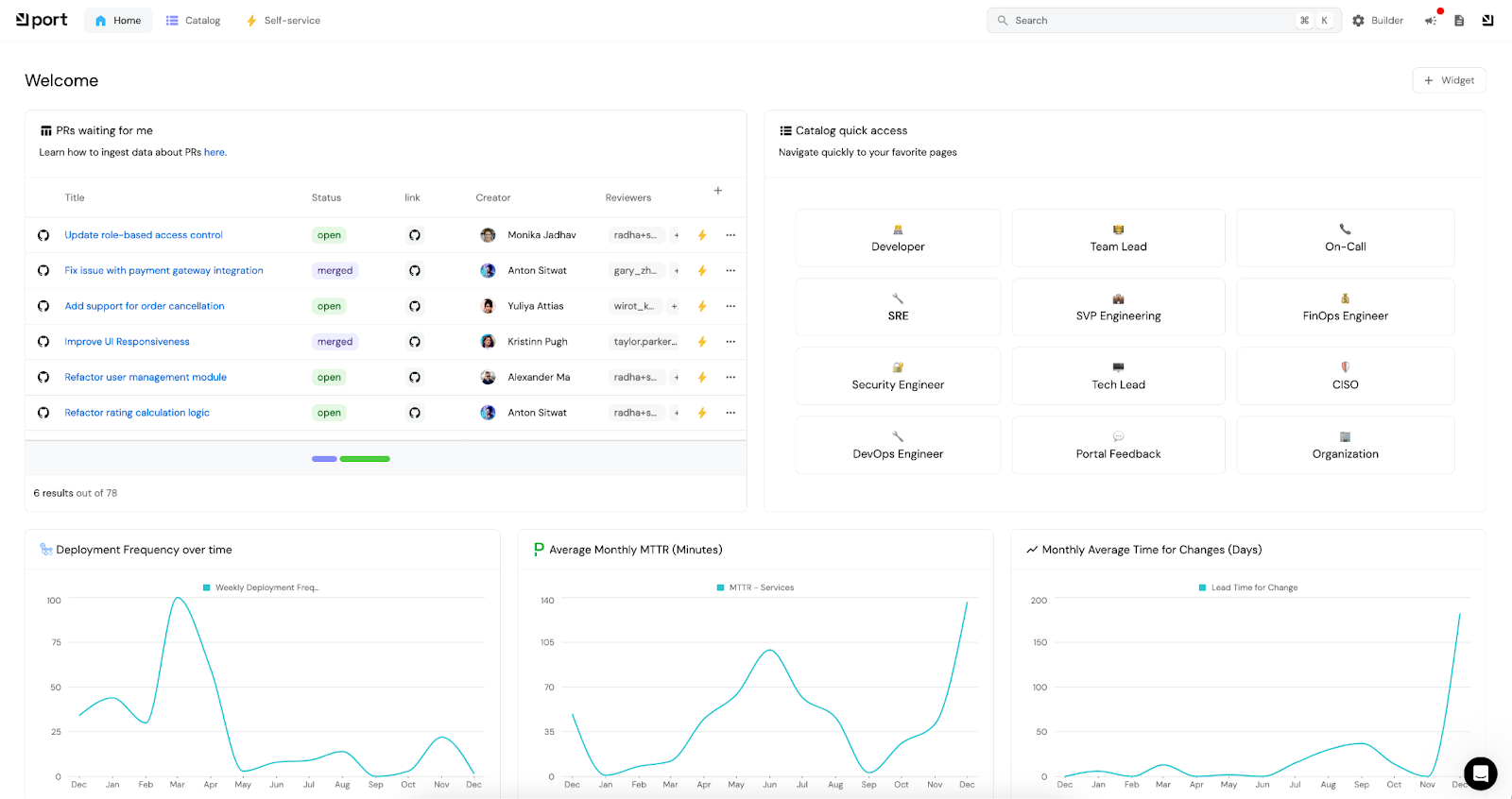
Port’s portal enhances collaboration between development and operations teams: SREs can build developer self-service actions that provide golden paths to developers, which means you can ensure that all of your standards are met, and your production environments are well-managed. Simultaneously, this frees you up to focus on higher-level strategic tasks like preventing future incidents and outages.
{{cta_1}}
10. Backstage
Backstage is an open-source platform for building your own internal developer portal. The source code was originally built by Spotify and is now part of the CNCF.
Founded in 2020, Backstage was one of the first internal developer portals available to address the emerging challenges with DevOps now associated with platform engineering. With software templates, SREs have an easier time suggesting, implementing, and enforcing standards, which can help you smooth out your deployment process and may result in fewer incidents overall.

Backstage is known for its flexibility and extensive plugin ecosystem. Many of these plugins revolve around monitoring, observability, reliability, and performance, but they can only provide data in individual silos by tool. This makes it difficult to model and query your stack data and draw insights from multiple sources.
Conclusion
We categorized these 10 tools for site reliability engineers into four groups: monitoring/observability, on-call and incident management, configuration and automation, and internal developer portals. Each of these tools provides SREs with the necessary capabilities to build robust incident responses, ensure and improve production readiness, and maintain high security and coding standards.
By leveraging these tools, SREs can effectively monitor, automate, and manage their systems, ensuring that they meet the demands of modern infrastructure and application environments.
Check out Port's pre-populated demo and see what it's all about.
No email required
.png)
Check out the 2025 State of Internal Developer Portals report
No email required
Contact sales for a technical product walkthrough
Open a free Port account. No credit card required
Watch Port live coding videos - setting up an internal developer portal & platform
Check out Port's pre-populated demo and see what it's all about.
(no email required)
Contact sales for a technical walkthrough of Port
Open a free Port account. No credit card required
Watch Port live coding videos - setting up an internal developer portal & platform

Book a demo right now to check out Port's developer portal yourself
Apply to join the Beta for Port's new Backstage plugin

It's a Trap - Jenkins as Self service UI



Further reading:

Learn more about Port’s Backstage plugin
Build Backstage better — with Port
Example JSON block
Order Domain
Cart System
Products System
Cart Resource
Cart API
Core Kafka Library
Core Payment Library
Cart Service JSON
Products Service JSON
Component Blueprint
Resource Blueprint
API Blueprint
Domain Blueprint
System Blueprint
Microservices SDLC
Scaffold a new microservice
Deploy (canary or blue-green)
Feature flagging
Revert
Lock deployments
Add Secret
Force merge pull request (skip tests on crises)
Add environment variable to service
Add IaC to the service
Upgrade package version
Development environments
Spin up a developer environment for 5 days
ETL mock data to environment
Invite developer to the environment
Extend TTL by 3 days
Cloud resources
Provision a cloud resource
Modify a cloud resource
Get permissions to access cloud resource
SRE actions
Update pod count
Update auto-scaling group
Execute incident response runbook automation
Data Engineering
Add / Remove / Update Column to table
Run Airflow DAG
Duplicate table
Backoffice
Change customer configuration
Update customer software version
Upgrade - Downgrade plan tier
Create - Delete customer
Machine learning actions
Train model
Pre-process dataset
Deploy
A/B testing traffic route
Revert
Spin up remote Jupyter notebook
Engineering tools
Observability
Tasks management
CI/CD
On-Call management
Troubleshooting tools
DevSecOps
Runbooks
Infrastructure
Cloud Resources
K8S
Containers & Serverless
IaC
Databases
Environments
Regions
Software and more
Microservices
Docker Images
Docs
APIs
3rd parties
Runbooks
Cron jobs


